Suppose that 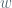
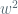

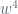
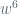

What can we say if we drop the guarantee that all cycle lengths divide 12?
Posted by: JBL | August 5, 2015
Permutation cycle type puzzle
Posted in Combinatorics | Tags: cycle type, cycles, permutations, puzzles
Posted by: yanzhang | February 16, 2013
Defense Against the Dark Arts: the Reverse Regression Effect
Much like our harmonious world, imagine a world populated with blue and green men living as brothers, ignoring the difference of the color of their skin. Much like our exciting world, both blue and green men get educated, go into the real world, and get jobs. One day, a green activist tells you that according to a recent study, for every given education level, blue men receive much higher salary on average than green men, a clear sign of discrimination against the greens — why should equally educated green men not be paid as much as blue men? After leaving you indignant and disappointed, a blue activist tells you that according to another study, for every salary level, green men are less educated than blue men, a clear sign of discrimination against the blues — why should blue men study harder in school than green men to get the same rewards for their work?
The punchline, of course, is that the two studies come from the same data. Judea Pearl mentions it as a throwaway comment in a general talk “The Art and Science of Cause and Effect,” which I read in his great work Causality. In particular, the paper referenced was Goldberger’s 1984 paper Reverse Regression and Salary Discrimination, with actual data demonstrating the effect (though with a different color palette). I find it surprising that Pearl would dedicate an entire chapter in Causality to Simpson’s Paradox but only one comment in the talk to this effect. While it is somewhat similar to Simpson’s Paradox (which I may talk about some other time), they are decidedly different in origin and I find this phenomenon much more relevant, prominent, and chilling. Let me explain. Read More…
Posted in Probability, Statistics | Tags: causality, Probability, reverse regression effect, Simpson's Paradox, statistics
Posted by: yanzhang | December 9, 2012
On Distances and Codes
I recently attended an interesting talk by Henry Cohn at the MIT combinatorics seminar on a certain class of (not necessarily linear) codes that include many of the classical creatures we know and love, such as the Hamming, Golay, and Reed-Solomon codes. This classification seeks to concretely capture the vague idea of “robustness” that people familiar with these codes would feel from working with them. A cute little discussion came up and I wish to record it here and possibly obtain some new ideas. Though the discussion was only tangentially related to the main ideas of Henry’s presentation, I find the question very natural. Read More…
Posted in Algorithms, Analysis, Combinatorics | Tags: codes, coding theory, Combinatorics, distances, finite fields, Gram matrix
Posted by: JBL | August 12, 2012
FindStat
In addition to the usual array of excellent talks and posters at FPSAC this year, there was a presentation by Chris Berg and Christian Stump on their new combinatorial statistic finder FindStat. It’s intended to serve as a sort of OEIS but for combinatorial statistics, i.e., integer data associated to combinatorial objects like permutations or partitions. In fact, though, it’s potentially much more powerful: for example, if you give a statistic on permutations, it not only checks its database of permutation statistics but also pushes the statistic through various combinatorial maps (like RSK) and then checks whether the statistic arises from some statistic on other combinatorial objects (like partitions). Like the OEIS, they solicit contributions from the community. It’s still in a very rudimentary stage, but I think it has a lot of promise. Or as Yan asked at the end of the presentation, “Why are you guys so awesome?”
Posted in Combinatorics | Tags: Computer algebra, FPSAC
Posted by: JBL | June 19, 2012
PRIMES 2012
At the end of May there was a two-day conference at MIT for the PRIMES program. About 30 high school students presented the research they’ve done over the last 6 months, as part of collaborative teams including grad students and sometimes undergrads, professors and post-docs at MIT and a few nearby universities. The quality of the work overall was quite impressive, even without taking into consideration that it was primarily performed by high school students. The talk abstracts are available on the PRIMES website; the papers that result will go online some time in December or January. You can read last years’ papers here.
Several contributors to this blog were mentors of PRIMES students: my students Ravi and Nihal presented some very nice work on generalizations of pattern avoidance in alternating permutations; this extends work in my thesis as well as work of Julian West and collaborators on shape-Wilf equivalence. Steven’s student Sheela presented work that’s a continuation of a project she began last year on the representation theory of Cherednik algebras. Yan’s student Aaron (who also is my coauthor in work based on his PRIMES project from 2011) presented his work studying the number of ways to put a graded poset structure on a given graph. As I understand it, this question comes from work of Yan on adinkras, and is both natural and apparently unstudied. The cutest result Aaron presented was the following: if G is a graph all of whose cycles are generated by its 4-cycles then the number of graded poset structures on G is 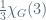
Posted by: yanzhang | March 16, 2012
Whitney Sum Formula and Exponentiation
I’m alive, just a bit antisocial – I’ve been spelunking in the wonderful caves of classifying spaces and group cohomology, which really got me to revisit my horrible algebraic topology fundamentals. I’m still a toddler in this field, but I think I’m beginning to take baby steps so I hope Haynes Miller and my other topology teachers (Anatoly, Dustin, Nick, etc.) would be eventually proud.
I just wanted to share a very short and simple insight today that made me very happy thanks to the Whitney sum formula: taking total Stiefel-Whitney classes are like exponentiating bundles (because taking total Stiefel-Whitney classes of a direct sum of two bundles becomes multiplication of the total Stiefel-Whitney classes of the individual bundles. This is “well duh” type of information to seasoned topologists, but to me this is exciting for several reasons: Read More…
Posted in Algebra, Geometry & Topology
Posted by: Steven Sam | January 18, 2012
Some talks
Unfortunately things have gotten more busy so I haven’t been writing on the blog. However, I found a new way to prepare talks that I really like: I type out my notes in a way which I hope is readable to someone who has not been to the talk. It is halfway between an expository paper and lecture notes and the advantage is that I have a product which I can share on my webpage (and I find it more useful than slides — I am starting to dislike slides presentations for seminar talks). Anyway, I’ll advertise some of these here (I’ve never actually posted about my own research on this blog, so it’s a first!):
1. I’ve been working with Laurent Gruson and Jerzy Weyman on finding geometric interpretations for orbits in “Vinberg 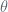
2. A separate project with Weyman involves trying to understand Koszul homology for certain classes of determinantal-like ideals. The motivation comes from trying to classify minimal free resolutions over quadric hypersurface rings and in trying to understand a certain result of Koike and Terada in combinatorial representation theory. I’m giving a talk on this tomorrow at Michigan (notes).
It’s a bit time-consuming, but I think preparing notes like this can be very useful, especially for projects which haven’t been finished yet (it helps me gain direction). I hope more people try it!
-Steven
Posted by: JBL | December 4, 2011
(3+1)-avoiding posets
Yan and I recently put a paper on the arXiv that enumerates the graded (3+1)-avoiding posets. In this post, I kill the adjective “graded” and talk a bit about what (3+1)-avoiding posets are and why they’re interesting. If you don’t know what a poset is, I’ve included the definition in Note 0 at the bottom of the post.
As with any object as general as posets, we are mostly interested not in results about all posets, but rather in finding particular families of posets with interesting or unexpected properties. One such family of posets are the (3+1)-avoiding posets. These are the posets that do not contain four elements, say a, b, c, and d, such that a < b < c and d is incomparable to the other three. A short digression to explain the name “(3+1)-avoiding”: one natural class of posets are the chains, finite total orders like the first example in the previous paragraph. A natural name for the chain with 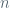
Posted in Combinatorics | Tags: graph theory, posets
Posted by: yanzhang | November 23, 2011
On Being Naive
I gave a talk at the MIT applied math seminar recently. Some people wanted a blog post, so here it is.
Some of my mathematical hobbies include probability and machine learning. I have recently realized that many simple but effective ideas of these fields really all come from one thing: an independence assumption. It was only until I saw the same example in several different guises, however, before I really caught on. As something Occam would surely approve of, the extreme naiveté this approach embraces can actually go a long way. Our key player is simple: we say that 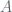
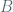
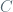
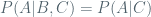
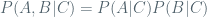
Posted by: lewallen | August 20, 2011
Positivity, Dynamics, Knots
Some of my research last year had to do with notions of “positivity” in Heegaard Floer homology and knot theory (a phrase which I’m borrowing from a paper of Matt Hedden). As a simple example of positivity, a braid (and more generally, a knot) is called positive if it has a diagram containing only positive crossings:

Posted in Uncategorized
Categories
- Algebra
- Algebraic Geometry
- Algorithms
- Analysis
- Category Theory
- Combinatorics
- Commutative Algebra
- Computer Science
- Differential equations
- Dynamical systems
- General
- geometry
- Geometry & Topology
- Machine Learning
- Matryoshka Problems
- Non-mathematical
- Probability
- Representation Theory
- Shoulda Series
- Statistics
- Uncategorized
